News
- The paper releasing SpeakerGuard has been accepted by IEEE Transactions on Dependable and Secure Computing (TDSC), 2022.
About
This is the official webpage for paper Towards Understanding and Mitigating Audio Adversarial Examples for Speaker Recognition accepted by IEEE Transactions on Dependable and Secure Computing (TDSC), 2022.
In this paper, we systematically investigate transformation and adversarial training based defenses for speaker recognition systems (SRSs) and thoroughly evaluate their effectiveness using both non-adaptive and adaptive attacks under the same settings.
In summary, we make the following main contributions:
-
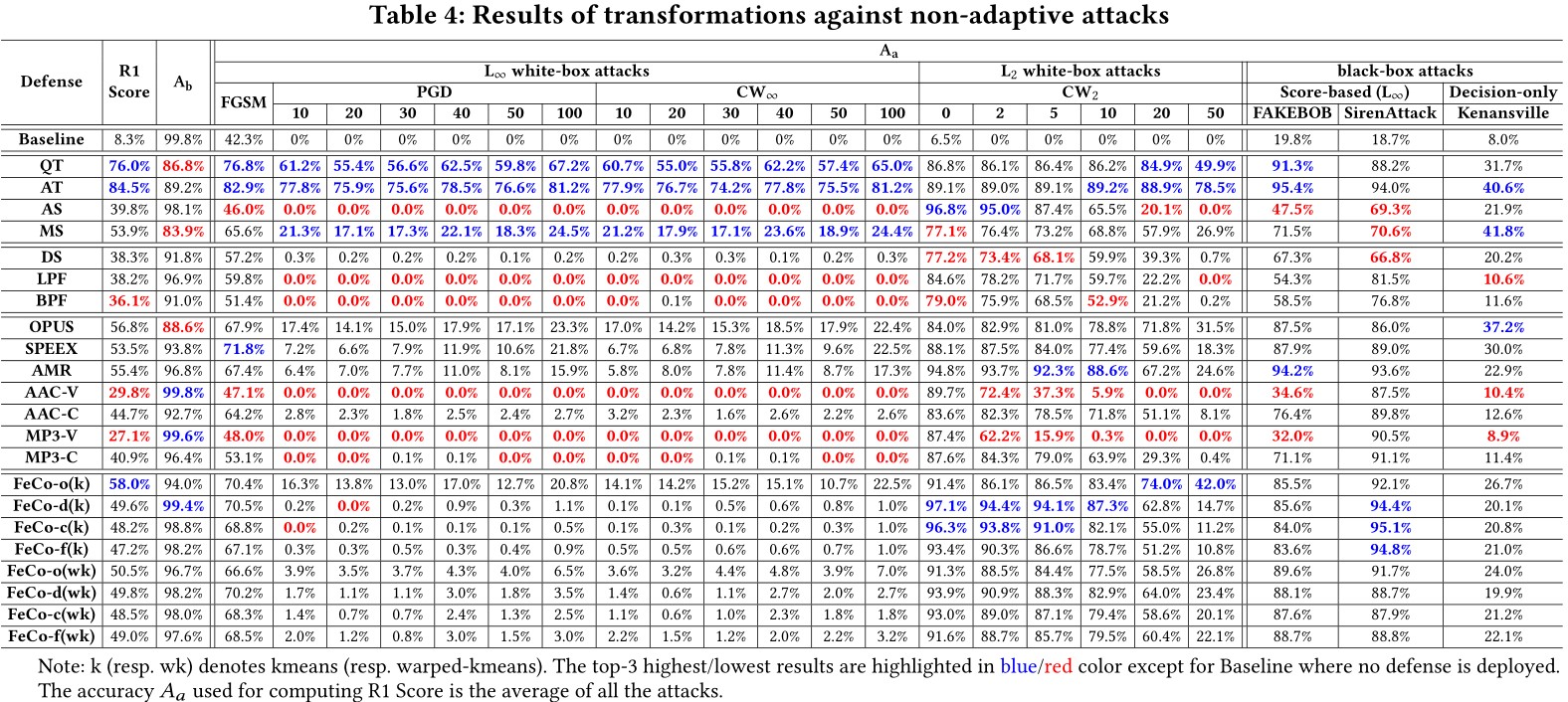
We perform the most comprehensive investigation of transformation based defenses for securing SRSs according to the characteristic of audio signals and SRS’s architecture and study the impact of their hyper-parameters for mitigating adversarial voices without incurring too much negative impact on the benign voices.
-
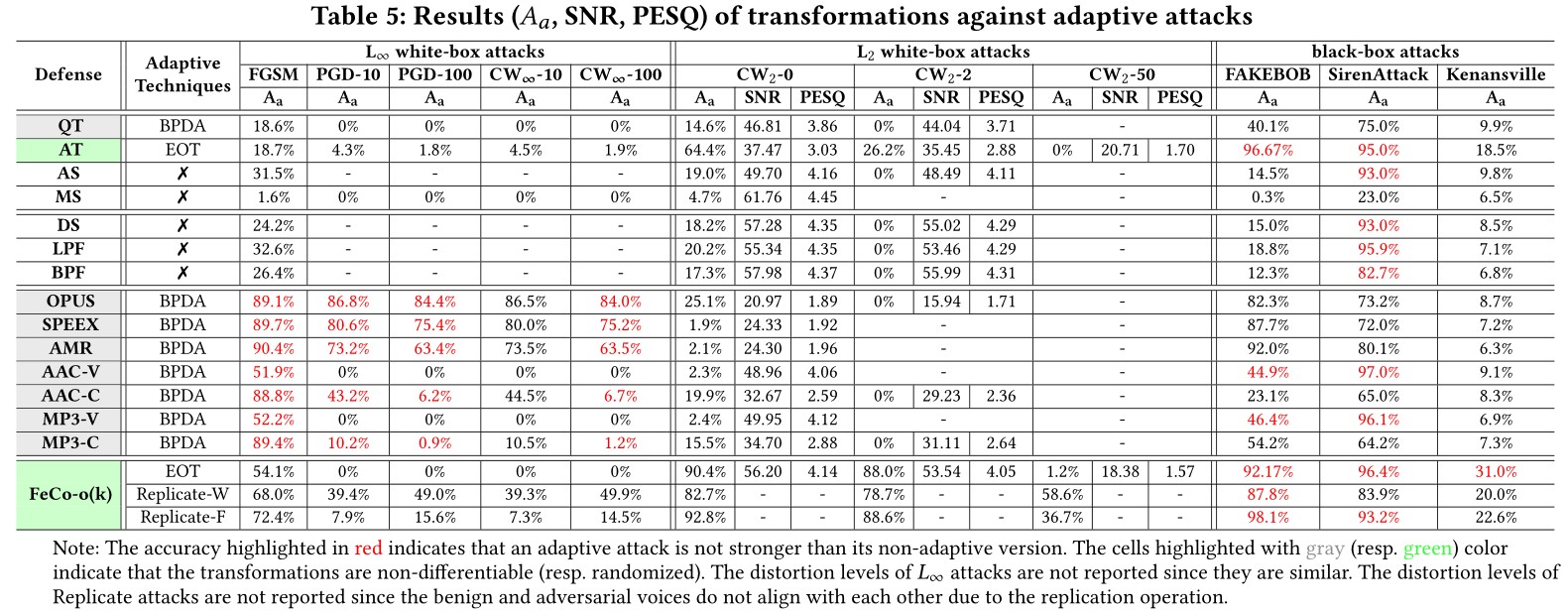
We thoroughly evaluate the proposed transformations for mitigating recent promising adversarial attacks on SRSs. With regard for best practices in defense evaluations, we carefully analyze their strength, on both models trained naturally and adversarially, to withstand adaptive attacks.
-
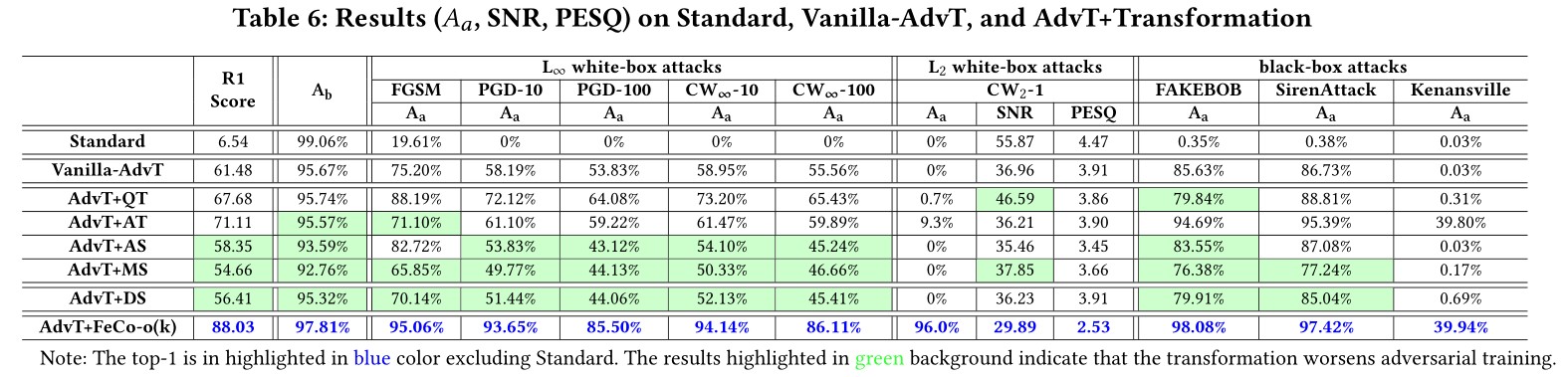
Our study provides lots of useful insights and findings that could advance research on adversarial examples in this domain and assist the maintainers of SRSs to deploy suitable defense solutions to enhance their systems. Particularly, we find that our novel feature-level transformations FeCo combined with adversarial training is the most robust one against adaptive attacks.
-
We develop SpeakerGuard, the first platform for systematic and comprehensive evaluation of adversarial attacks and defenses on speaker recognition. It features mainstream SRSs, proper datasets, white-box and black-box attacks, widely used evasion techniques for adaptive attacks, evaluation metrics, and diverse defense solutions. We release our platform to foster further research in this direction.
Empirical Study Result
Transformation against Non-adaptive Attacks
Transformation against Adaptive Attacks
Transformation+Adversarial-Training against Adaptive Attacks
Audio Files
We provides our audio files for percetibility measurement and other purposes.
-
Adversarial audios produced by adaptive attacks against different defenses:
For adversarial audios, after unzip, the directory A-B/X/X-Y/Z means the audios are crafted by the attack X with the attack paramter Y against the defense A with the defense parameter B on the speaker Z. For example, FeCo-ok-kmeans-raw-0_2-L2/FGSM/FGSM-0_002-50/1998 means the audios are crafted by FGSM attack with $\varepsilon=0.002$ and EOT_size $r=50$ against the defense FeCo with the defense parameter $cl_m=kmeans$ and $cl_r=0.2$ on the speaker 1998.
Platform: SpeakerGuard
To perform the above empirical study, we establish a security evaluation platform for speaker recognition.
Want to re-produce our experimental results, do something new with our platform, or even extend SpeakerGuard? Go to Code for SpeakerGuard for detailed instructions.